Updated (2022-01-01): Added stage.
At Community we are building a platform that will allow you to have meaningful conversations with large audiences … at scale!!!
The architectural backbone is a shared-nothing micro-services architecture, that uses an event-bus for state propagation.
To avoid any kind of 2-phase-commit shenanigans we are publishing events at-least-once (not exactly-once). That means our services need to be able to and are able to deal with dublicated events gracefully (by ignoring them).
It also means, that we have to retry publishing an event on the event-bus, if the publish fails. One reason the publish can fail (especially when you run long event replay jobs) is that the AMQP infrastructure (connections, channel, …) dies.
The tech-stack is: Elixir, AMQP and RabbitMQ.
The interesting thing is that, if you use AMQP out of the box and create a connection and a channel and start publishing events (e.g. from a gen-server), you will not get notified when the infrastructure has a problem (e.g. dies).
Instead you will get a Cannot find process error/exception next
time you try to use the infrastructure (e.g. publish an event).
So … what is going on here?
After investigating and understanding it the answer is simple: the Elixir/Erlang AMQP implementation creates an Erlang process for the connection and a process for the channel on that connection and when there is a problem these two processes die.
So far so good …
The problem is that out-of-the-box these processes are not linked to the processes that created them, which makes detecting that something went wrong (and retrying what ever failed) kind-a interesting.
At the end we came up with the following approaches to deal with this …
- Use
try/catcharound every statement that uses a connection or a channel (catching theexit) - Use
Process.flag(:trap_exit, true)AND link the connection process to the process that created the connection and handle theexitmessage - Take a step back and use a
supervisorto restart the connection AND retry whatever needs retrying - Take it one step further and use
gen_stageswith asupervisor
The good news is there is a repo that has all of the code in it that shows how this works (the implementations for all the different approaches are on different branches)!!!
Let’s talk about these approaches …
Using try/catch
Obviously easy to implement and easy to understand. Retrying whatever you did is also easy, because you know what operation you tried/failed.
But … you need to wrap every AMQP call in a try/catch. Not so nice.
Using trap_exit (and Process.link())
With this you can (just) listen for the exit message to arrive in
your inbox and handle it with handle_info. On one hand this is much
nicer, but … retrying whatever failed becomes harder (you probably
need to put some info into the state, so that you know what to retry,
when you get/handle the exit).
We also realized that just pattern matching on :exit/:infrastructure_died
is not good enough, because there is small race condition, where the next
publish happens before you can trap the exit from the connection/channel
gen_server and in that case you get the treaded :exit/:noproc again (and
need to handle that too).
Using a supervisor
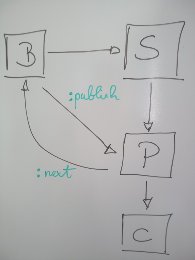
That’s obviously a nice solution. For that you create a supervisor and a worker and give the work to-do (e.g. publish this batch of events) to the worker. The supervisor supervises the worker and if the worker has any kind of problem getting the work done the supervisor will restart the worker and retry the work (the batch).
This will also cater for the case that we descibed above, where the
publisher can exit with at least two abnormal reasons (:infrastructure_died
and :noproc).
Using gen_stages (with a supervisor)
A couple of weeks ago I had a chance to review this work with some of my colleagues at Community and the conclusion was that this can be improved by using gen_stages.
The implementation is elegant and can recover from various infrastructure problems with connections and channels.
But there is one thing that you need to think about. One reason why the supervisor approach above works well is that we start a worker per batch (in sequence, one after the other), means when the worker dies and gets restarted the batch to process gets passed to it again (automatically).
Which gives us the at-least-once semantic we want and need.
gen_stage pipelines work differently. The publisher is started once and will keep on asking for batches until it is stopped or it dies.
When the publisher is restarted (after it died) it will ask for the
next batch. It does not know, that it failed to process a batch
and/or what that batch was/is.
The solution can be simple: Just use the head of the pipeline (in our case the batcher) to hold on to a copy of the current batch until the tail of the pipeline (in our case the publisher) has confirmed that it has processed the batch. If that ack has not happened and the pipeline asks the batcher for the next batch, the batcher can resend the batch that was (apparently) not correctly/entirely processed.

Initial implementations of this had very elaborate trapping and linking
and message passing. The main lesson learned was: Do not try to do the
work for the OTP. Let the OTP do the work for you. In our case that
means/meant: Let the worker fail! Let the supervisor restart it. And
do not use any of the “internal” messages (e.g. :exit/:normal) to tell
the batcher to send the next batch. Instead use a custom message (e.g.
:next). Even more, even further: Use the eco-system! This problem is
not new and can be solved using existing capabilities (e.g. gen_stages).
Again: If you want to find out about the details how this works, please take a look at the repo.
Happy reliable, at-least-once eventing …